
Google Analytics is in many ways, a complete tool. From collecting data from your website, processing and aggregating it to giving you high-quality reports from which you can learn a great amount of things about your web data. The strength of Google Analytics lies primarily in its ease of use, with a few clicks here and there combined with a few copy pastes, we get our data spoon-fed to us.

Google Analytics is a great tool, but it does have its limitations. Think of it as like a black hole, the version given to us by the movie Interstellar. You do not have the means to look inside it but what you can do is study it’s radiations, these radiations in themself are quite useful but there’s only so much you do with them. Here at MarketLytics, we are constantly on the lookout for new ways to get the most out of our clients data. With a tool like GA you can’t actually access the raw data, or peer inside the black hole, as i’d rather put it; unless you send data to BigQuery or another database there is limited room for innovation. This is where Snowplow Analytics saves the day.
Enter Snowplow Analytics, an open-source enterprise event-level analytics platform that enables data collection from multiple platforms for advanced data analytics.It is a lot similar to tools like Google Analytics 360 or Mixpanel, with one major difference; you can now access the hit-level raw data previously unattainable through traditional means.
It is designed to work on Amazon Web Services, utilizing the power and scalability the cloud-based platform has to offer. One major downside of this paradigm is that for the relatively uninitiated, it is a headache to configure and get up and running. However, luckily for us, we came across this detailed and a rather lengthy tutorial by Simo Ahava on duplicating Google Analytics data and sending it to our Snowplow setup.
The tutorial is quite thorough and complete, If you haven’t already set up and configured it to send your Google Analytics data, we recommend that you carefully comb through it. If at some point you get stuck, as we did countless times, just scroll up and make sure you did everything according to the blog. If you’re still stuck, check the official documentation on Github or the Snowplow Community Forum on Discourse.
Market Basket Analysis
Now that we have Snowplow properly configured, it’s time to extract some meaningful insights from it. For this tutorial, we shall be doing Market Basket Analysis (MBA), which is essentially a modeling technique based on the theory that if you buy a certain group of items you are more likely to buy another group of items. The end result is a set of rules that we can use to find out which items go together, this technique has a number of useful applications. E-commerce websites can now know what products they should place together to increase revenue, Content-focused websites can understand what content they should put in the same section or in close proximity.
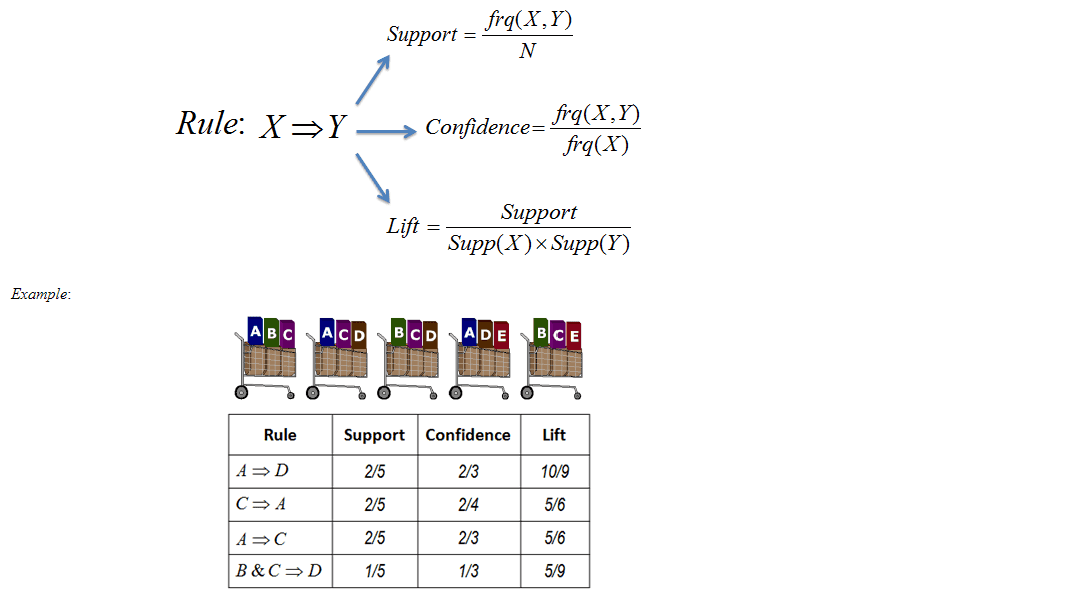 source: UofT
source: UofT
In order to understand the mathematics behind MBA, you can read this article
MarketLytics is Digital Analytics consultancy and we run a blog which attracts a lot of traffic. Which again, isn’t the ideal application for MBA but the steps shown below can be applied for E-commerce data as well.
We are using R for this tutorial, if you’re not familiar with the language then we recommend you hold on back on implementing this until you learn the basics.
0) Installing the required packages
We need to install the packages which we will need for this tutorial.
install.packages('tidyverse');
install.packages('arules')
install.packages('arulesViz')
install.packages('dplyr')
install.packages(‘RPostgreSQL’)
Now load the respective packages using the library function.
library(tidyverse) library(arules) library(arulesViz) library(dplyr) library(RPostgreSQL)
1) Querying Redshift
library(RPostgreSQL) drv <- dbDriver("PostgreSQL") con <- dbConnect(drv, host="host.us-east-2.redshift.amazonaws.com", port="5439", dbname="dbname", user="read_only", password="###########")
First we establish a connection with our Redshift DB using the RPostgreSQL library.
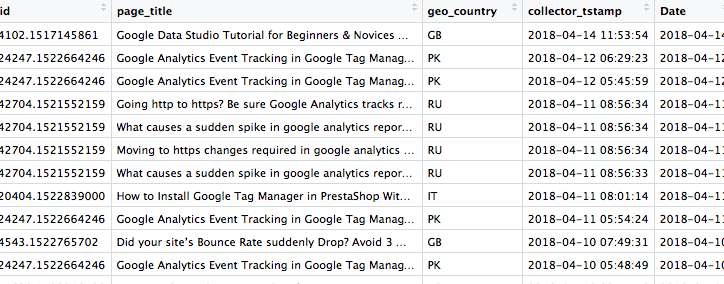
web_data <- dbGetQuery(con, "SELECT usr.client_id, ae.page_title, ae.geo_country, ae.collector_tstamp FROM atomic.com_google_analytics_measurement_protocol_user_1 AS usr JOIN atomic.events AS ae ON usr.root_id = ae.event_id ORDER BY ae.collector_tstamp DESC;")
The query here is where all the magic is taking place, we are getting the data we would need for modeling. As mentioned before this is data from a blog and not an ecommerce site. For E-commerce data, we can use the following query.
SELECT usr.client_id, ae.ti_sku, ae.geo_country, ae.collector_tstamp FROM atomic.com_google_analytics_measurement_protocol_user_1 AS usr JOIN atomic.events AS ae ON usr.root_id = ae.event_id ORDER BY ae.collector_tstamp DESC;
Your query should return you a dataframe similar to the one shown below
2) Web Data ETL
In order to bring this data into a format we can apply Market Basket Analysis to it, we need to put the data through a number of transformations
web_data$Date <- as.Date(web_data$collector_tstamp) web_data < web_data[complete.cases(web_data),] web_items <-ddply(web_data,c('client_id','Date'), function(df1)paste(df1$page_title, collapse = ",")) web_items$client_id <-NULL web_items$Date <- NULL colnames(web_items) <- c('items')
Once you’ve successfully executed all these commands, your web_items dataframe should look something like this.

Now we will save this dataframe as a separate CSV
write.csv(web_items,”web_basket.csv”,quote = FALSE, row.names = TRUE)
3) Market Basket Analysis
web_tr <- read.transactions("web_basket.csv",format = 'basket',sep =',') web_rules <- apriori(web_tr,parameter = list(supp =0.001,conf =0.8)) web_rules <- sort(web_rules, by ='confidence',decreasing = TRUE)
In these lines of code, we load our CSV as a transaction, and then apply the apriori algorithm to find all the rules with minimum support of 0.001 and confidence above 0.8. We then arrange the rules in descending order of confidence.
We can use the inspect() function to see our rules

The inspect tells us a number of useful things about our rules. In order to understand what this output means let’s pick the first rule and dissect it.
Rule [1] tells us that we can say with a 100% confidence, that anybody who visits lhs ‘Properties & People – MarketLytics’ page will also visit rhs ‘Getting Started with Mixpanel: Events’ page. It also tells that this rule has a support of 0.001288475 and that this particular rule was obeyed a total of 9 times in our data.
Now that’s somewhat of a mouthful, and may be difficult to understand at first. In order to understand what the above statement means we need to define the terms in this context
Support: The ratio of times the two pages in Rule[1] appear in our search logs to all the pages viewed in our data i.e lhs+rhs/total_pageviews
Confidence: The ratio of number of pageviews for the page on lhs and number of views of the page on rhs to number of pageviews of the page on rhs i.e lhs+rhs/rhs.
Lift: The ratio of expected confidence to actual confidence, higher lift indicates stronger association.
Still confused? All this text seems a little too much to understand, so it’s better if we visualize this data to make more sense of it. This can be done quite simply using the ‘arulesViz’ library we imported. In order to visualize this data in the form of a graph, we use the following function:
plot(web_rules[1:5],'graph')
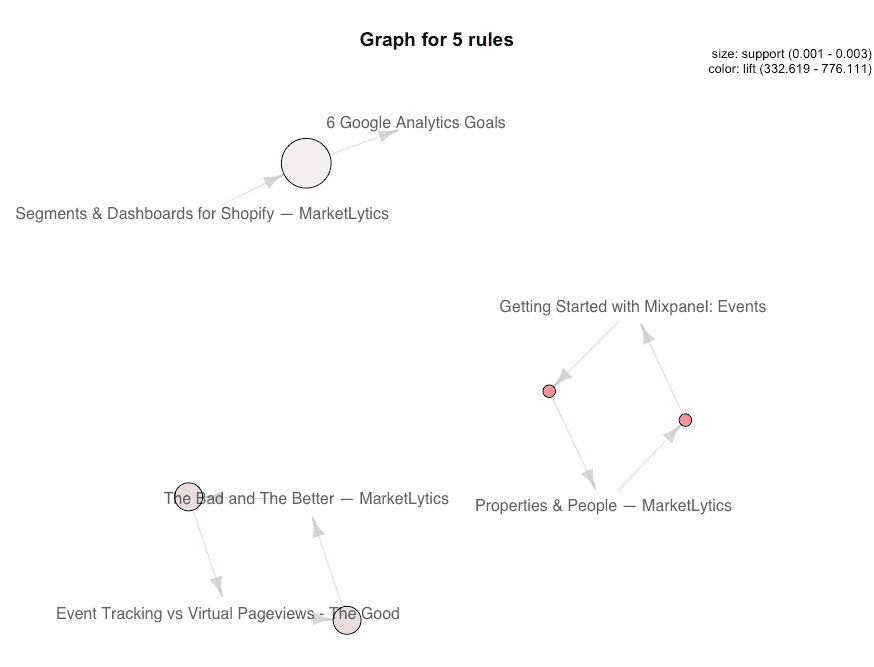
This graph essentially visualizes the set of rules we got before. And there you have it, Market Basket Analysis on Google Analytics using Snowplow. Keep in mind that this is only a bare-bones implementation of MBA, feel free to explore more options and the diverse features offered by the the libraries we’ve used in R.
Feel free to comment if you have any queries.





