In customer analysis, one of the most actionable insights a retail business with many offerings can get is the classification of customers by their behavior into segments based on the preferences that they exhibit in their interaction with the business. This is a kind of segmentation that we want to do based on what we learned from selling to them, without any prior assumption or expectation about their behavior. If we can successfully find common patterns in people’s preferences, and group them by their common tendencies, this can open the doors to many possibilities of marketing optimization, up-selling, re-marketing, and re-activation efforts.
To give a more concrete example, let’s say that a particular class of customers tends to have similar choices of what they would buy from a retail store, e.g mothers might go for groceries, cosmetics, along with baby products and snacks for kids. Dads might go for all the above minus cosmetics but also go for tools. Girls might go for groceries and cosmetics along with some other stuff. Given a traditional store with a counter, with the owner dealing with customers themselves, they will probably recognize their customers, know their preferences, and apply their experience to extrapolate for new customers. But if the retailer is an online store with tons of offerings, they will need a method to identify the classes of customers by their preferences, and once identified, could maybe up-sell them other products that they know a particular class of customers is interested in, or re-market to them with offers that would interest that class.
This seems like a classical case for clustering. A broad category of methods devised by statisticians (who are very smart people, btw) to classify observations by their similarities, rebranded in the current decade as ‘unsupervised learning’ by the ML crowd (sorry I couldn’t resist saying that, but they just went too far with this one).
Clustering: an overview
If you already know how clustering works, feel free to skip over this section.
““An intelligent being cannot treat every object it sees as a unique entity unlike anything else in the universe. It has to put objects in categories so that it may apply its hard-won knowledge about similar objects encountered in the past, to the object at hand.” – Steven Pinker, How the mind works, 1997”
The basic idea behind clustering is man’s most primitive learning ability. Early humans, for example, must have been able to realize that many individual objects shared certain properties such as being edible, or poisonous, or ferocious, and so on. Each noun in a language, for example, is essentially a label used to describe a class of objects that have striking features in common; thus, animals are called cats, dogs, horses, etc., and each name collects individuals into groups. Naming and classifying are essentially synonymous.
A loose definition of clustering could be “the process of organizing objects into groups whose members are similar in some way”. A cluster is, therefore, a collection of objects which are “similar” between them and are “dissimilar” to the objects belonging to other clusters. How the human intellect does that is so abstract that it’s impossible to have a machine mimic the process. But what if there was a way we can quantify characteristics of objects with numbers that can be used to compare between them? Then these dumb machines might still have a chance to serve us better, right?
Let me demonstrate this by example. Following is a graphic showing petal length on the x-axis, and petal width on the y-axis for 150 flowers of the iris family:
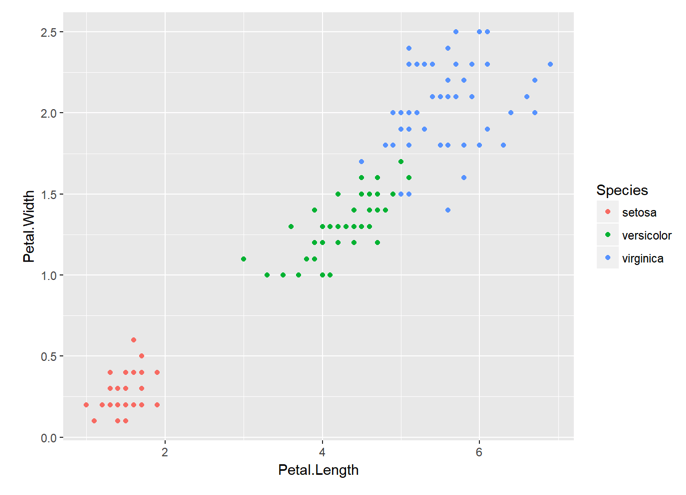
By these measurements, we can clearly see at least 2 groups, or as we would like to call them, ‘clusters’ of flowers by combinations of these two measurements. A machine as dumb as a computer can be instructed to measure the distances on this graph between each point, and see if there are distances that are close together, as they should be for observations in the same cluster, and others that are further, as they should be between observations from different clusters, and thus make two, or even three clusters from this data. The similarity and difference between the flowers here is designated as the distances measured between the observations of the two measurements we took.
Now, for what I mentioned in the title:
Cluster analysis uses similarities that we presumed between a set of objects, based on some scale to measure that similarity, and differences that have to be determined to define the boundaries of each cluster. It can be done a variety of different ways, of which the above was just a rudimentary example. Topic modeling is similar in the sense that it classifies corpora of text into ‘topics’. The basic assumption is that there is a likelihood of words occurring in specific patterns relative to some topics. Words can belong to different topics, and the topics can still be discerned based on the frequency of the occurrence of those words along with others. Similarly, a text can be composed of topics, and sub-topics and one topic can be a ‘central theme’ in one text while being a ‘sub-topic’ in another. With topic modeling approaches, we can find out how many topics to classify corpora of texts into, how much of each of those topics ‘contribute’ to a text in the corpus, and how much each word ‘contributes’ to each of those topics. So not like ‘hard’ clustering, but still a way to narrow down lots of texts into a number of groups by the similarity in the topics of their contents.
So how can I use it in customer analytics?
To give a little background, the client I was working for is a travel and tours portal, advertising lots of ‘experiences’ offered by various providers, e.g ‘day trip to xyz waterfalls’ and ‘abc island cruise’ etc. Now the assumption would be that people of particular interests would tend to prefer certain activities that can be identified by the occurrence of certain words in their descriptions. Consequently, when they visit the said client’s website, they are likely to browse through those certain activities that interest them. So if we could gather the descriptions of all the activities that they clicked on to view the details of, we would end up with let’s say, a ‘text’ composed of their primary interest, i.e. the ‘central theme’ of that text, and some other ‘subtopics’ representing their smaller interests.
Here’s an example: Follow the video graphic below.
 No points for guessing the similarity between these three activities!
No points for guessing the similarity between these three activities!
The person going through these activities is probably crazy about the water right? How do we know that?
How about ‘It’s obvious! Duh!’
But it would be fair to suggest that people who share this person’s interests will probably sift through activities that have similar words in their descriptions, right? The frequency of words that occur in all the activities they viewed will give a basis of forming a ‘cluster’ of similar people, for example people who love water sports, and that’s how we will group them.
Now all the customers that clicked on products, searched for activities, or viewed details of some, would not make a booking. In fact, the conversions would only be a small fraction, but if we could cluster users by their interests, inferred from these activities, we would know for each cluster the activities that were booked most, by people in that cluster that actually converted. This would provide a basis to infer what activities this group of customers, that probably shares interests, is most likely to actually buy, so we can target them with optimized advertisements for re-marketing.
Sounds cool? It is. While relying on ‘lookalike’ audiences for marketing provided by Facebook or Google is usually the closest bet in advertising for most businesses, and is also essential for marketing to new audiences, re-marketing specifically to people who had visited our website before, browsed some products and hence exposed their interests, with products that similar people actually bought will, in most cases yield a better proportion of conversions.
However, it is worth mentioning that for this job, I didn’t just use this one approach to optimize remarketing. The rest would probably be the topic of my upcoming blogs.